Core Architecture and You; The Importance of Storage Tuning on AMD CPU's


When evaluating storage performance, particularly in high-throughput and low-latency environments with local NVMe and NVMe-over-Fabrics (NVMe-oF), the CPU architecture becomes far more than just the background actor on stage. With AMD’s EPYC Genoa and particularly Turin families, we’re talking about platforms architected from the ground up to handle immense concurrency, bandwidth, and memory pressure—features that directly influence storage subsystem behavior. The real story is in how architectural choices around fabric, memory, IO die topology, and coherency models interface with what storage technologists care about most: consistency, queue saturation thresholds, and latency determinism.
Let’s start with fabric clock (FCLK). On Genoa and later, FCLK is decoupled from memory clock (UCLK) and can run at a fixed 2000 MHz, and is configurable via BIOS on certain platforms. This separation from DRAM frequency is a departure from the Zen 2/3 models where fclk and uclk parity was ideal for latency. In storage, especially with NVMe-oF where RDMA and PCIe DMA interactions are critical, having a stable and high FCLK keeps the inter-CCD and IO die communication latency predictable. This directly affects command completion latency and NVMe queue responsiveness under load, especially for random workloads or when under mixed IO pressure.

With EPYC Genoa and Turin’s IO die design, you’ve got a centralized IO die with 128 lanes of PCIe Gen5 and 12 DDR5 memory channels, giving you an absurd amount of total bandwidth potential. For local NVMe storage, PCIe Gen5 is obviously a massive win, especially when populating multiple high-throughput drives per NUMA node. But what gets interesting is the PCIe lane bifurcation flexibility and how it can be used to balance NVMe devices evenly across multiple CCDs. Misalignment here (say, skewing all devices to one side of the socket) causes added hop latency, as requests have to travel from compute dies across the IO die’s internal fabric and back again, which also incurs higher power and introduces backpressure on that IO die's internal switch.
The CCD count and layout on Genoa—up to 12 CCDs with 96-128 cores—has implications for NVMe performance when paired with high I/O workloads. CCDs are discrete silicon chiplets with their own L3 cache and physical distance from the IO die. Threads pinned to different CCDs accessing the same NVMe device can introduce variable latency, especially when the BIOS/firmware settings don’t aggressively co-locate storage threads to CCDs nearest the PCIe controller in use. For local NVMe, this is often a non-issue at low queue depths but becomes critical at QD32+ where queuing and inter-CCD coherence overheads start to erode latency gains. For NVMe-oF, which often scales better with aggregate queue depth and multi-core parallelism, this inter-CCD factor must be considered in software stack tuning (e.g., SPDK core affinity or kernel thread placement).
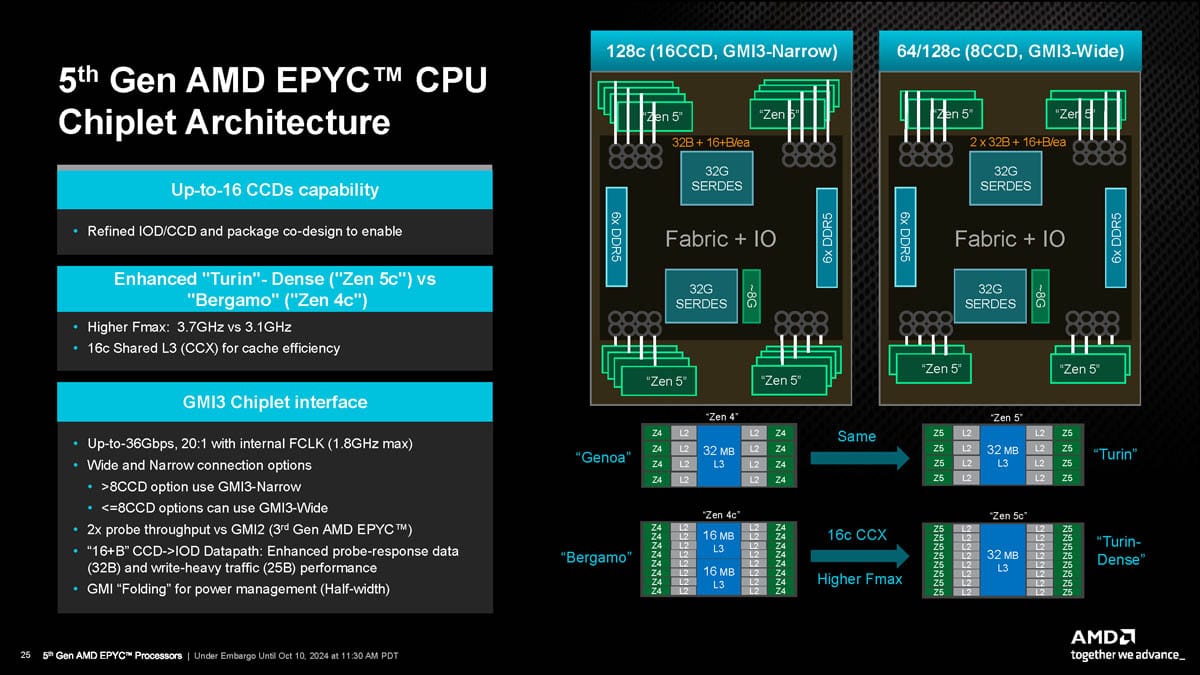
Now, when we step into EPYC Turin (Zen 5), there’s a fundamental shift. Along with the increase to 16 CCDs (128-192 cores), the CCDs are redesigned for better cache hierarchy and latency behavior, and memory prefetching has been improved to anticipate and service DMA operations more efficiently. Turin also introduces an enhanced IO die that improves PCIe lane arbitration and brings in support for CXL 2.0, which has future implications for composable storage. The CCD-to-IO die latency has also been slightly reduced, which helps real-world NVMe performance consistency, particularly in systems that are heavily multi-tenanted or with heavy concurrent NVMe queue activity.
DRAM speed and memory controller enhancements in both Genoa and Turin are significant. DDR5 introduces higher bandwidth, but what matters more for storage is the effect on latency and NUMA locality. Since both Genoa and Turin support up to 12 channels, memory bandwidth per socket is no longer a bottleneck—unless you’re overdriving the CPU with storage-optimized workloads at full PCIe saturation while simultaneously hosting memory-intensive apps (hello, AI pipelines). NVMe-oF can be sensitive to DRAM latency on the host side, especially when using kernel bypass libraries like SPDK or DPDK that pre-allocate pinned buffers in hugepages. If you’re not binding those buffers to local memory channels relative to the NIC and CPU cores, you’re going to see variance in tail latency and sometimes lower aggregate IOPS depending on the DMA behavior of the NIC.
From a coherency standpoint, EPYC does not use a shared LLC like Intel's monolithic Xeon dies. Instead, you get a fixed amount of L3 per CCD, and depending on workload, that can be a blessing or a curse. NVMe command queues tend to live in L3 if they’re hot enough, but with cross-CCD workloads, that data must either migrate through the IO die or get evicted entirely. In contrast, Intel Sapphire Rapids (SPR) and Emerald Rapids (EMR) use a mesh architecture with a unified LLC, which simplifies cache coherency but often at the cost of per-core latency.
However, Intel does have higher single-thread performance and AVX-512 capabilities(sorta), which helps in storage use cases that rely heavily on compression, encryption, or checksum calculations inline. That said, due to the lower PCIe lane count for Intel’s SPR and EMR CPUs compared to either Genoa or Turin, you may need a dual socket system to reach the same number of NVMe drives per system. This could add latency from needing to access drives over Intel’s UPI fabric along with added mesh arbitration which can negatively impact NVMe-oF under sustained queue depth, particularly with many small I/O operations.
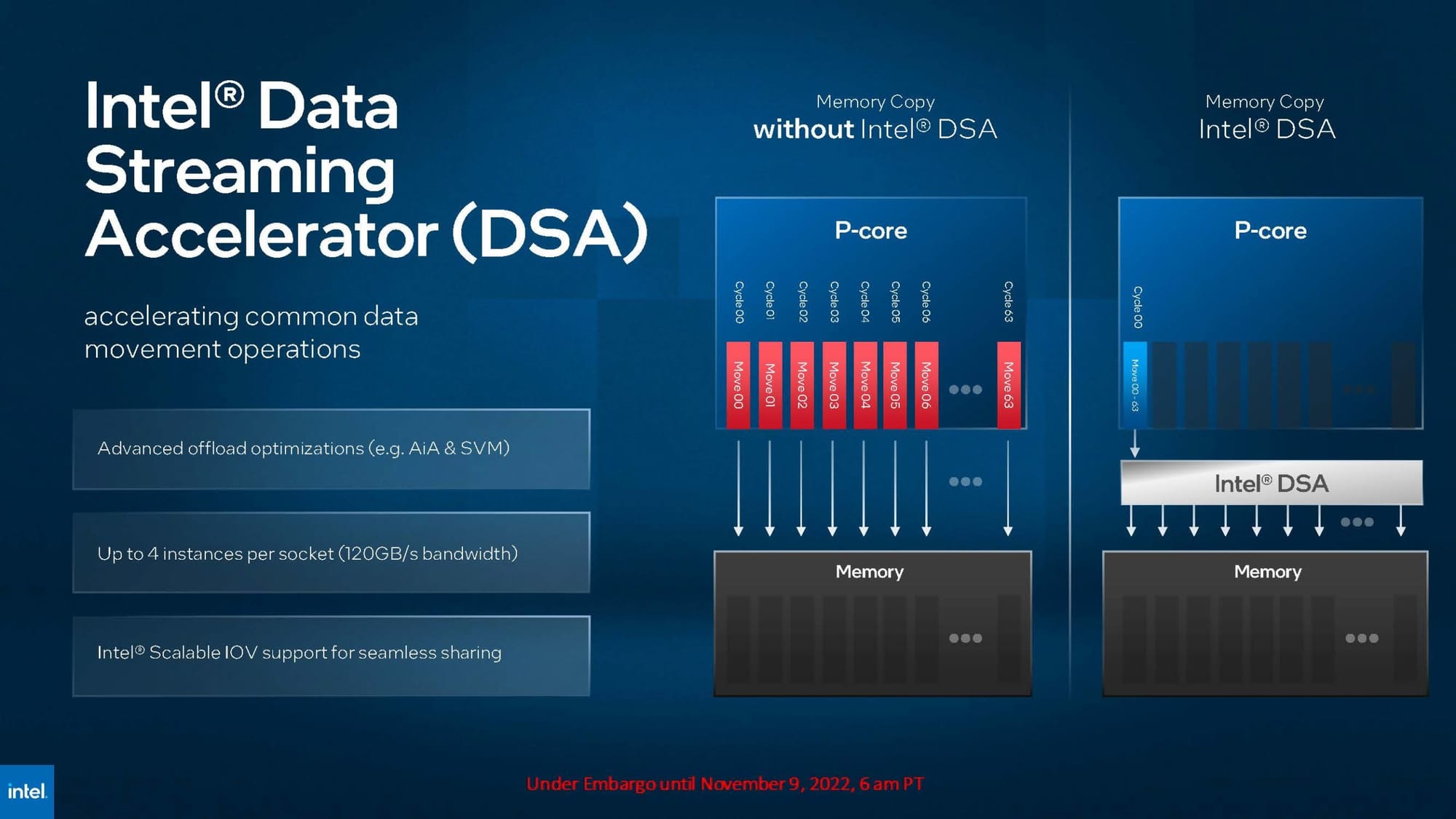
Intel's DSA (Data Streaming Accelerator) does win out in certain storage workflows—particularly in inline checksum, pattern detection, and data movement in RAID-like systems. AMD doesn’t yet have a direct analog in the Turin generation, though Genoa and Turin can use broader PCIe device offload strategies via SmartNICs or DPUs, particularly in SPDK+NVMe-oF setups.
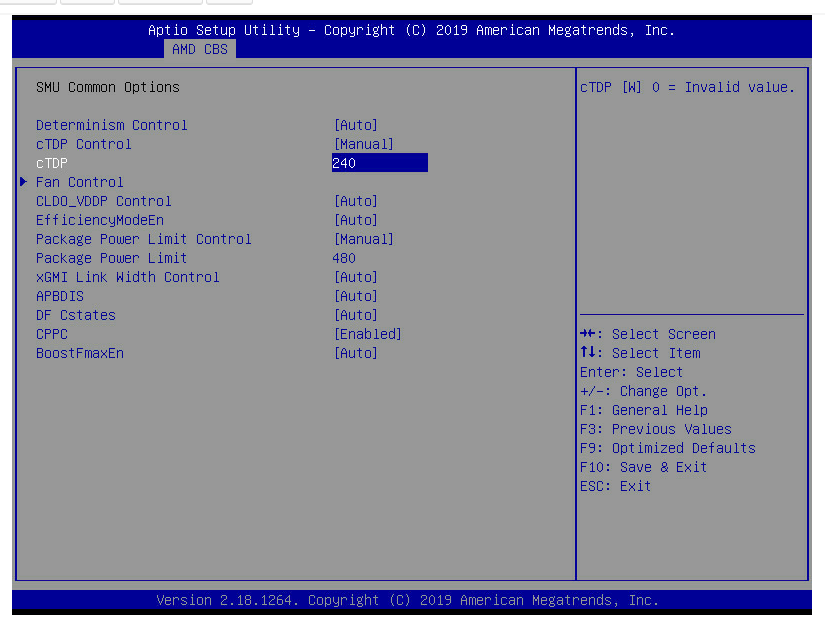
Then there’s the configurability. AMD gives far more granular control over power and performance bias settings. You can configure cTDP and adjust socket-level P-state behavior to favor IO responsiveness over raw compute. Genoa and Turin both allow for fabric and IO prioritization over compute in firmware, something Intel mostly abstracts. When fine-tuned correctly, Genoa/Turin can actually outperform Intel in storage-tail latency consistency and sustained throughput by keeping the IO and memory paths hotter longer, even if the cores are underutilized.
All this to say, AMD's architecture—chiplet-based with high-core-count, massive memory bandwidth, and advanced IO—creates a very deterministic, tunable environment for NVMe and NVMe-oF when you respect the NUMA domains, IO mapping, and memory locality. Intel is still ahead in some compute-bound IO tasks, and its monolithic design makes it easier to "just work" in smaller-scale deployments. But for high-scale storage platforms, especially those pushing 400GbE+ or full NVMe-oF enclosures, Genoa and Turin give you far more knobs, consistency, and fabric headroom to build bleeding-edge storage infrastructure that’s tuned to the workload.